Streamlined Data Processing: Linking Databricks, GitHub, and Azure Data Factory
A Collaborative Approach with Databricks, GitHub, and ADF


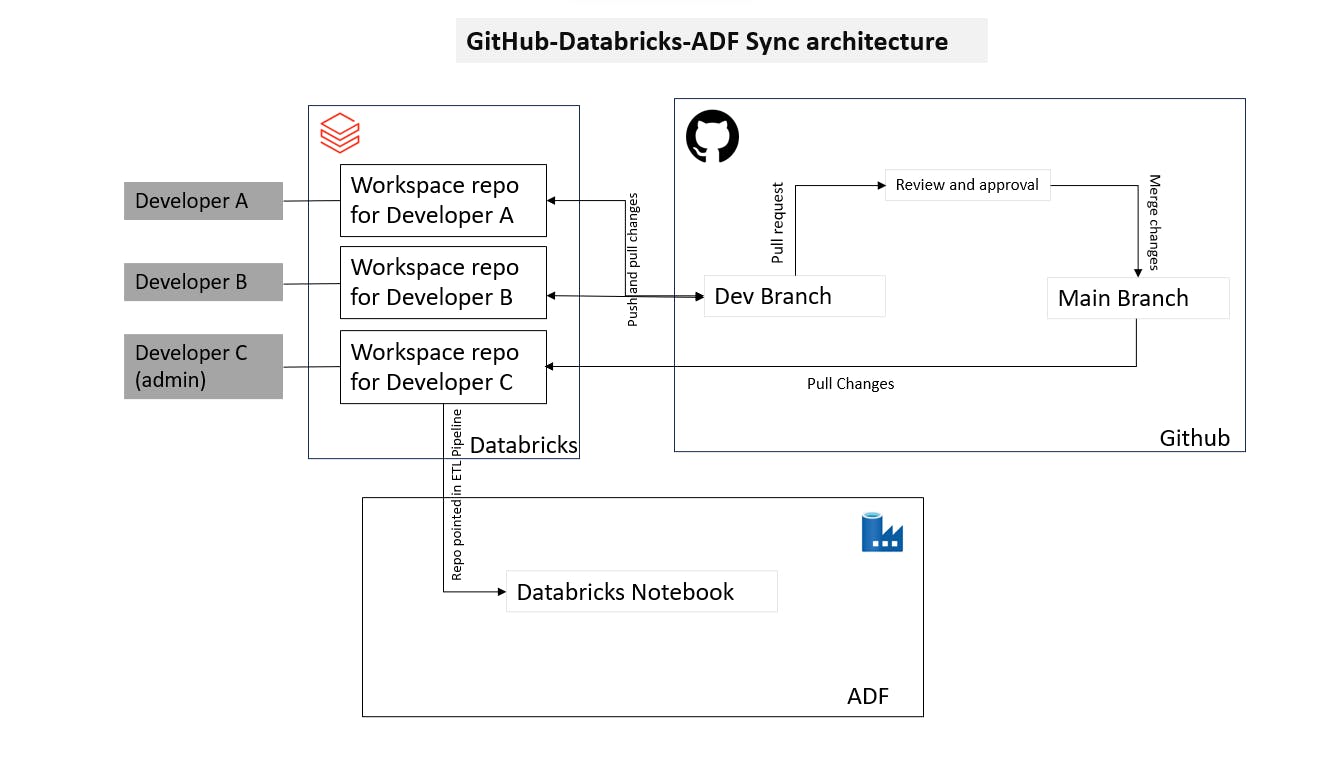
This blog dives into building a collaborative data processing pipeline using Databricks, GitHub, and Azure Data Factory (ADF). We'll explore how to set up this architecture with clear steps for three developers (A, B, and C) with varying access levels.
Roles and Responsibilities
Developer C (Admin):
Creates the main Git repository in GitHub.
Sets access permissions for A and B (read/write).
Creates the corresponding workspace in Databricks and links it to the GitHub repository.
Manages the ADF pipeline (ideally with version control).
Developers A & B:
Clone the GitHub repository to their local environments.
Make changes on their development branches.
Submit pull requests to merge changes into the main branch.
Setting Up the Workflow
GitHub Repository:
C creates a public or private repository on GitHub.
C grants A and B "write" access to the repository.
Databricks Workspace:
C creates a workspace in Databricks.
C links the Databricks workspace to the GitHub repository. This establishes version control for Databricks notebooks.
Local Development:
A and B clone the GitHub repository to their local machines.
They can now work on separate development branches within the cloned repository.
Code Changes and Pull Requests:
A and B make changes to the notebooks in their development branches.
Once complete, they submit pull requests to merge their changes into the main branch.
C (or another designated reviewer) reviews the pull requests and approves them if the changes meet quality standards.
Azure Data Factory Pipeline:
C creates an ADF pipeline and references the notebook from the main branch of the GitHub repository linked to Databricks.
Important Note: While C's repository is used for the pipeline, any changes merged into the main branch by A or B will be reflected in the ADF pipeline due to the Git integration with Databricks.
Benefits of this Architecture:
Version Control: Git provides a central repository to track changes and revert if necessary.
Collaboration: Developers can work on separate branches without interfering with each other's work.
Automation: ADF automatically executes the pipeline whenever changes are merged into the main branch, ensuring a streamlined and up-to-date data processing workflow.
We'd love to hear your thoughts on alternative design or architecture approaches in the comments below!